What's Cooler Than Deep Research? An Army of Deep Researchers!

The Opening Salvo
Imagine a single detective trying to solve 360 different cases simultaneously—each requiring deep expertise in different domains, from financial fraud to art theft to cybercrime. Now imagine instead deploying 360 specialized detectives, each laser-focused on their specific case, sharing insights when their investigations overlap. This is the difference between using a single AI research tool and deploying an army of specialized deep researchers.
In the rapidly evolving landscape of AI-powered research, organizations face a paradox: while tools like OpenAI's Deep Research offer unprecedented capabilities for autonomous investigation, their general-purpose nature can paradoxically limit their effectiveness for organizations with specific, complex informational needs. The solution isn't to abandon these powerful tools—it's to multiply them, specialize them, and orchestrate them into a coordinated intelligence network. This isn't theoretical—it's the approach we use internally at Mosaiq to produce comprehensive market intelligence that would otherwise require teams of analysts working for weeks.
TL;DR
- Scale beats sophistication: Deploying 360 specialized AI researchers (72 targets × 5 research types) delivers more actionable insights than a single generalist agent
- Attention is finite: Specialized agents maintain laser focus on their domains, avoiding the attention dilution that plagues general-purpose AI
- Human-in-the-loop ensures accuracy: Review systems where humans validate, modify, or redirect research prevent hallucinations from entering production data—maintaining accountability for data quality
- Modularity enables evolution: Independent research modules can be updated, replaced, or expanded without disrupting the entire system
- API costs < alternative costs: While running hundreds of deep research calls increases compute spend, it's a fraction of what manual research would cost in time and human resources
Why One-Size-Fits-All Falls Short
OpenAI's Deep Research represents a remarkable achievement—it can autonomously conduct multi-step research, analyze vast amounts of text and images, and generate comprehensive reports in minutes rather than hours. In testing, it achieved 26.6% accuracy on complex research tasks, outperforming many competitors. Yet for organizations tracking competitive dynamics across global markets, this general capability becomes a limitation.
Consider a real-world scenario we encountered: analyzing generative AI adoption across 72 global digital marketplaces. A single research agent, no matter how sophisticated, must context-switch between understanding Nordic regulatory frameworks for one platform, Southern European market dynamics for another, and Chinese language nuances for a third. Each context switch dilutes attention, potentially missing critical details that a specialized agent would catch.
The challenge isn't the tool's capability—it's the architecture of deployment. Just as modern software moved from monolithic applications to microservices, AI research benefits from decomposition into specialized, focused agents.
The Army of Deep Researchers Framework
The architecture we've implemented at Mosaiq deploys five distinct types of specialized research agents across multiple target organizations, creating what we call an "Army of Deep Researchers." Here's how it works in production:
The Five Divisions
Market Intelligence Corps: These agents build comprehensive company profiles, tracking market position, growth metrics over multi-year periods, and competitive dynamics. They understand the difference between market share and mind share, between reported revenue and actual market impact.
Talent Scout Battalion: Specialized in analyzing hiring patterns and team composition, these agents don't just count job postings—they decode the skills being sought, identify leadership hires that signal strategic shifts, and map the actual implementation capacity of organizations.
Innovation Reconnaissance: These agents track technology adoption from announcement through implementation. They distinguish between press release promises and production reality, identifying which companies have moved beyond pilots to actual deployment.
Solution Analysis Unit: When Innovation Reconnaissance identifies an implemented solution, these specialists conduct deep dives—understanding not just what was built, but how it was built, who built it (in-house vs. partnered), and what metrics demonstrate its impact.
Strategic Intelligence Division: These agents analyze leadership communications—earnings calls, investor presentations, executive interviews—extracting not just what leaders say about AI, but how their narrative evolves over time, revealing true strategic commitment versus performative adoption.
The Multiplication Effect
When deployed across 72 organizations, these five agent types create 360 focused research initiatives. Each maintains deep context about its specific domain and target, executing with consistent precision rather than starting fresh with each query.
This isn't just parallelization—it's specialization at scale. A Hiring Research agent focused on a North American platform becomes expert at parsing specific applicant tracking systems and decoding Silicon Valley hiring signals. Meanwhile, its counterpart analyzing a European platform masters the nuances of EU recruitment terminology and local tech talent markers. The agents don't "learn" or evolve—they execute their specialized prompts with unwavering focus, while human reviewers ensure accuracy.
Architectural Design Principles
Principle 1: Modular Independence
Each research agent operates as an independent module with its own:
- Prompting strategy optimized for its domain
- Validation criteria specific to its research type
- Output schema standardized for downstream processing
This modularity means a breakthrough in analyzing leadership communications doesn't require restructuring the entire system—just updating the Strategic Intelligence agents.
Principle 2: Semantic Tool Specialization
Different research types require different capabilities. Market Intelligence agents need web search and data parsing tools. Solution Analysis agents require code interpretation capabilities to understand technical implementations. By matching tools to agent types, each division operates with exactly the capabilities it needs—no more, no less.
Principle 3: Human-in-the-Loop Quality Gates
The system incorporates review interfaces where human experts serve as the final arbiters of data quality:
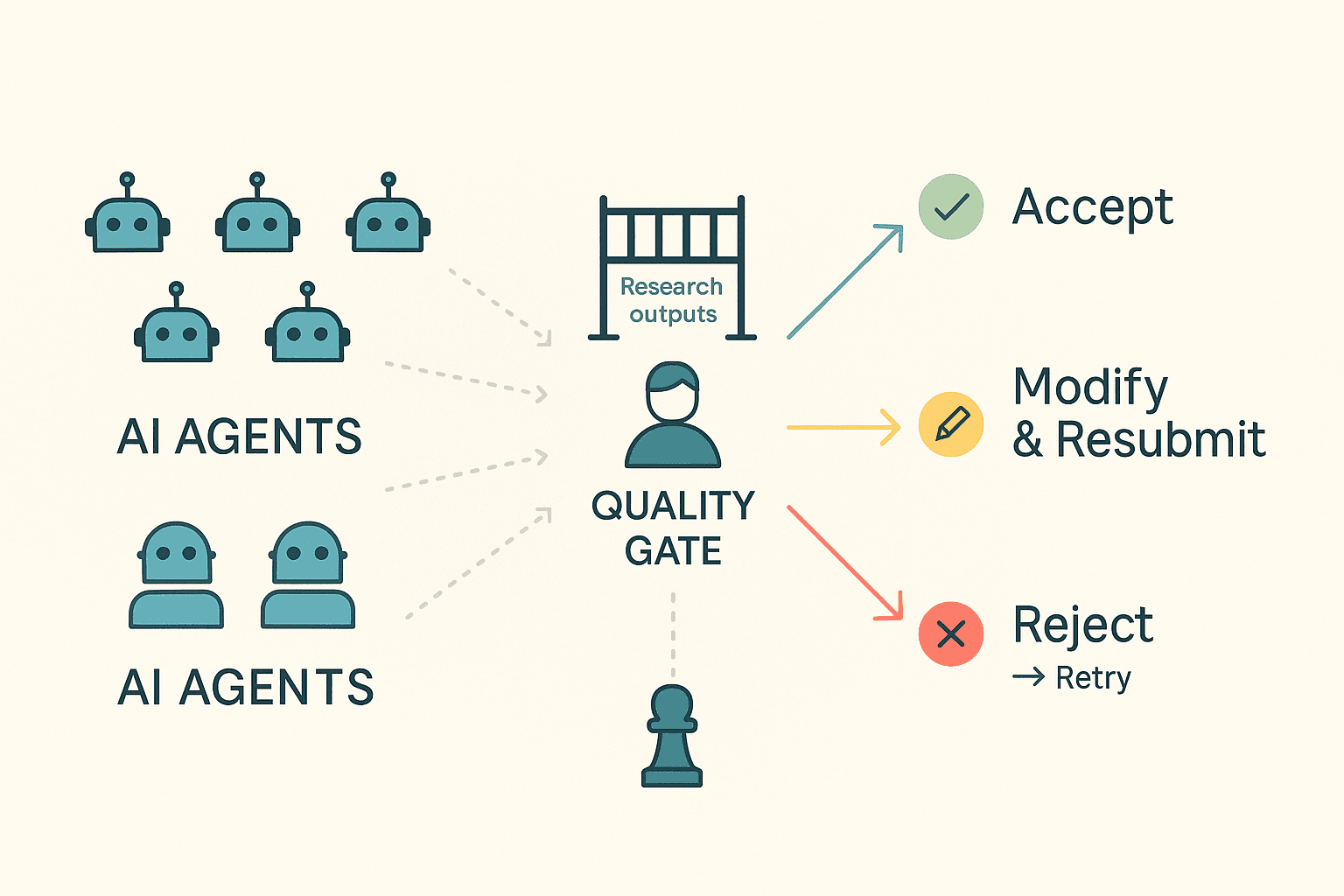
Human-in-the-Loop Quality Gate Process
- Validate claims against evidence before accepting research into production datasets
- Modify findings when domain expertise reveals nuance AI missed
- Redirect investigation when initial research surfaces unexpected paths
- Reject and retry when quality doesn't meet standards
This isn't about training the models—they remain static. It's about accountability. No hallucinated data, no unverified claims, no AI-generated fiction enters our final datasets without human verification. Think of it as editorial fact-checking for AI research—ensuring that what goes into production is accurate, verified, and defensible.
Principle 4: Asynchronous Orchestration
Rather than sequential research (analyze Company A completely, then Company B), the system operates asynchronously. While Strategy agents analyze Q3 earnings calls, Adoption agents investigate product launches, and Hiring agents parse new job postings. This temporal parallelization dramatically reduces time-to-insight.
The Attention Advantage
In transformer-based AI models—the architecture underlying tools like GPT—attention is literally all you need. But attention is also finite. When a single agent attempts to research everything about everyone, its attention becomes diluted, like trying to follow 360 conversations at a cocktail party simultaneously.
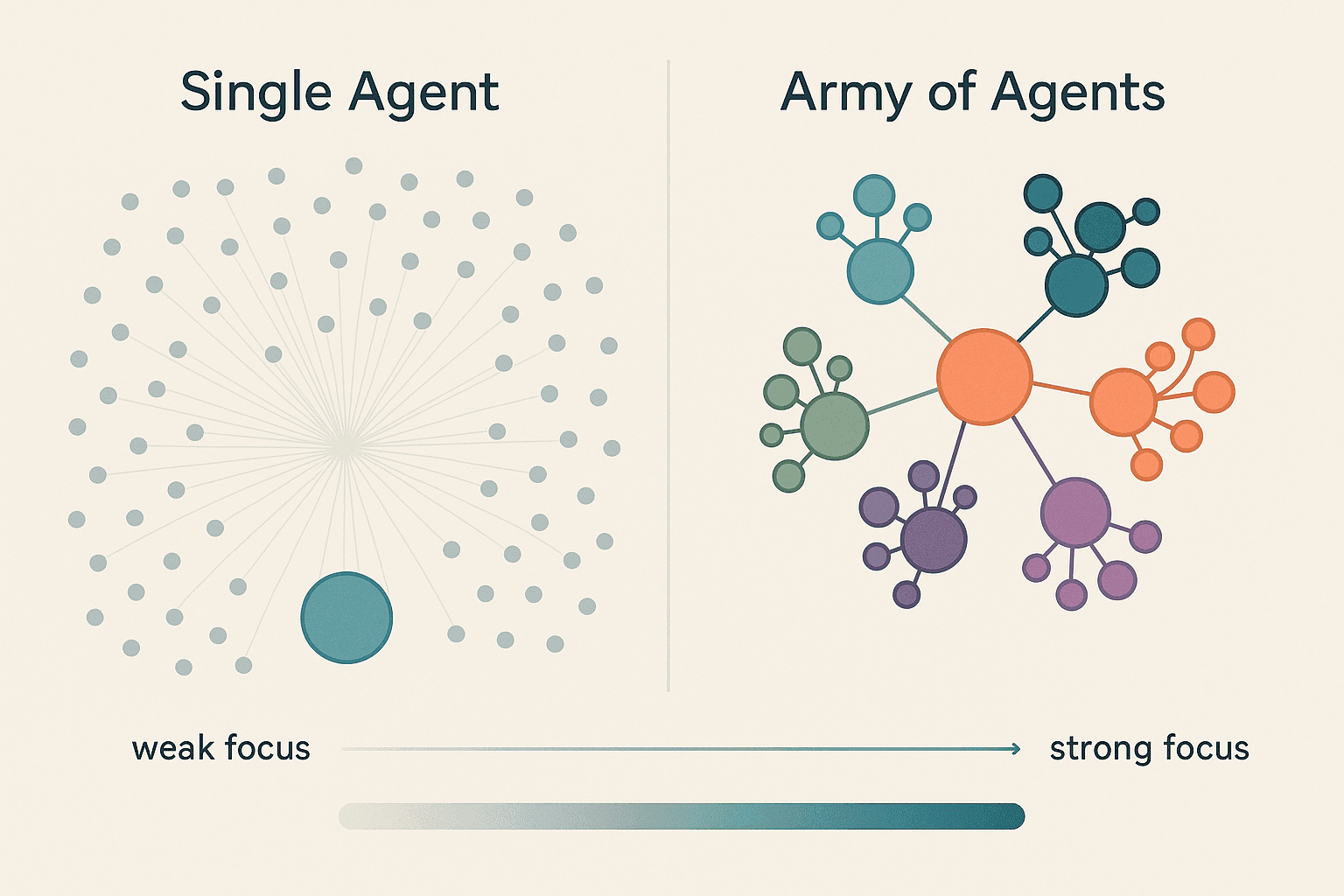
Single Agent vs Army of Agents - Attention Focus Comparison
Specialized agents maintain focused attention within their domains through carefully crafted prompts and constraints. A Hiring Research agent is prompted to distinguish between "AI Engineer" (often traditional ML) and "GenAI Engineer" (specifically generative models). It's instructed that when European companies post roles requiring "LLM experience," they're likely serious about generative AI, while "ML experience" might mean recommendation systems.
This focused attention is built into the architecture from day one. Each agent type has specialized prompts containing domain-specific instructions, terminology, and validation criteria. The consistency comes not from learning, but from architectural design—each agent always applies the same specialized lens to its research domain.
Real-World Implementation Patterns
Pattern 1: The Cascade Trigger
Innovation Reconnaissance identifies that a major European platform has implemented "AI-powered virtual staging." This triggers:
- Solution Analysis agent investigates the specific implementation
- Hiring Research checks for recent computer vision engineer hires
- Strategy Research reviews leadership statements about the feature
- Market Intelligence examines competitive response
Each agent contributes its specialized perspective, creating a multi-dimensional understanding impossible for a single generalist.
Pattern 2: The Validation Loop
When Market Intelligence reports that a platform grew revenue 47% year-over-year, the claim enters human review. The reviewer notices the figure includes an acquisition and modifies the finding to note "organic growth of 22%, acquisition-adjusted growth of 47%." This nuanced understanding ensures accuracy in the final dataset—the models themselves don't learn from this correction, but our production data remains clean and defensible.
Pattern 3: The Competitive Mesh
Adoption agents tracking different companies in the same region identify patterns. When three platforms in the same geographic market launch natural language search within six months, the system surfaces a regional competitive dynamic that company-specific research would miss.
Counterpoints and Limitations
This architectural approach isn't without challenges:
Coordination Overhead: Managing 360 agents requires robust orchestration infrastructure. Failed agents need retry logic. Rate limits need careful management. Results need aggregation and deduplication.
API Costs Are Real: Running hundreds of specialized deep research agents isn't cheap—we typically see costs in the thousands of dollars per comprehensive market analysis. But context matters: a single senior analyst might cost $200-300 per hour, and producing similar depth of research manually would take weeks, not hours. The API costs are a fraction of the alternative.
Human Review Bottleneck: The human-in-the-loop quality gates that prevent hallucinations can become a bottleneck at scale. Organizations must balance review depth with throughput. At Mosaiq, we've found that the time invested in review is still orders of magnitude faster than traditional research methods, while ensuring zero hallucinations enter production data.
Integration Complexity: Different agent types may use different AI providers or models. OpenAI for deep research, Anthropic for analysis, Perplexity for real-time data. Managing these integrations adds architectural complexity—but also provides resilience through redundancy.
The Strategic Implementation Path
For organizations considering this approach (as we've refined through production deployments at Mosaiq):
Start with Critical Domains: Don't immediately deploy 360 agents. Identify your highest-value information needs and deploy specialized agents there first. Learn from this focused deployment before scaling. We typically start clients with 10-20 agents focused on their most pressing intelligence gaps.
Build Review Expertise: Human reviewers need domain knowledge to effectively validate AI research and prevent hallucinations. They're not training the models—they're ensuring accountability. Invest in training reviewers or partner with domain experts who understand both your industry and AI limitations.
Design for Evolution: Your information needs will change. Build systems that can add new agent types, retire obsolete ones, and adapt existing agents to new requirements. The prompts can evolve even if the models don't.
Calculate ROI Properly: Compare API costs not to "free" ChatGPT queries, but to the fully-loaded cost of human analysts producing equivalent research. Include the opportunity cost of delayed insights. Our clients typically see 5-10x ROI even with substantial API spend.
Consider Partnership: Designing and operating specialized AI research systems requires expertise in AI architecture, prompt engineering, and quality control workflows. At Mosaiq, we've operationalized these systems for multiple industries—turning months of research into days of computation plus review.
Beyond General Intelligence
The evolution from single AI assistants to armies of specialized researchers mirrors a broader pattern in technology: the move from monolithic to distributed, from general to specialized, from single-threaded to massively parallel.
Just as that detective agency would never assign one investigator to 360 cases, organizations shouldn't expect a single AI—no matter how sophisticated—to address all their informational needs with equal depth and precision. The future belongs not to artificial general intelligence solving everything, but to armies of artificial specialized intelligence, each excelling in its domain, coordinated to serve human decision-making.
The question isn't whether AI can conduct deep research—tools like OpenAI's Deep Research have proven it can. The question is how to architect AI research capabilities that match the complexity, specificity, and scale of real organizational needs. The answer, as we've proven in production at Mosaiq, is not one deep researcher, but an army of them.
In this new paradigm, competitive advantage doesn't come from having access to AI—everyone has that. It comes from deploying AI with the architectural sophistication to transform information overload into actionable intelligence, while maintaining human accountability for data quality. That's not just cooler than deep research. That's the difference between having information and having insight.
Yes, the API bills can be eye-watering. But when you're producing in hours what would take a team of analysts weeks to compile—with built-in quality controls that prevent hallucinations from contaminating your data—the economics become compelling. We're not replacing human judgment; we're amplifying human capacity to understand complex, multi-dimensional competitive landscapes.
For organizations ready to move beyond general-purpose AI to architected intelligence systems, the path forward is clear: specialize, scale, and orchestrate. The army of deep researchers isn't just a metaphor—it's an operational reality that we deploy daily at Mosaiq, transforming how organizations understand their competitive environment.
Ready to Transform Your Business?
Let's discuss how our AI-native solutions can deliver similar results for your organization. Schedule a discovery call to explore the possibilities.


